27.02.2023 - Studies

Now that the world has learned how well pattern recognition works through chat GPT, we ask how far pattern recognition through machine learning has advanced in financial markets.
Machine learning (ML) describes computer systems that can independently recognise patterns in data sets in order to make targeted decisions. Long before ChatGPT and Dall-E went viral, machine learning found its way into the financial markets. In this research, we document the current state of its application in financial markets.
Machine learning applications are the most advanced in securities trading, which has historically used algorithms at a very early stage. Buyers and sellers both benefit from efficient pricing and order processing.
The first applications are also appearing in risk management, although they are limited to orderly descriptions of the past without being able to derive predictions for the future. The ability of computers to structure large amounts of data independently brings the decisive advantage.
Price predictions, the holy grail of the financial market, are used with the help of machine learning by various hedge funds and also mutual funds. Large hedge fund houses such as Renaissance Technologies and Bridgewater Associates publish the theories behind their ML applications, although the concrete profitable methods are guarded like treasures. We think we can see that users are currently focusing on short-term predictions, which can be used in part to create profitable short-term-oriented trading strategies. ML approaches for forecasting the long-term development of individual stocks, as they could be used to compile portfolios that promise high returns over a long period of time, are not being successfully pursued in our estimation.
Machine learning gives financial market players a tool to reduce costs. However, forecasting future financial ratios and the development of sectors beyond a few days is still pie in the sky for the field of machine learning and artificial intelligence.
At the beginning of research into artificial intelligence in the early 1950s, practical applications were limited to programs that could perform simple, standardised calculations and were based on normative rule systems. For example, in 1951, the British computer scientist Christopher Strachey taught a computer the rules for the board game of checkers. Just one year later, Anthony Oettinger at Cambridge University presented the first self-learning programme: "Shopper" could shop in a model world of eight shops. When shopping for the first time, the programme went through the shops randomly, but partly remembered which articles were stored in which shop. If "Shopper" should subsequently get an article that he had remembered, he would go directly to the right shop. This was the birth of machine learning, the dominant sub-field of artificial intelligence (AI) today.
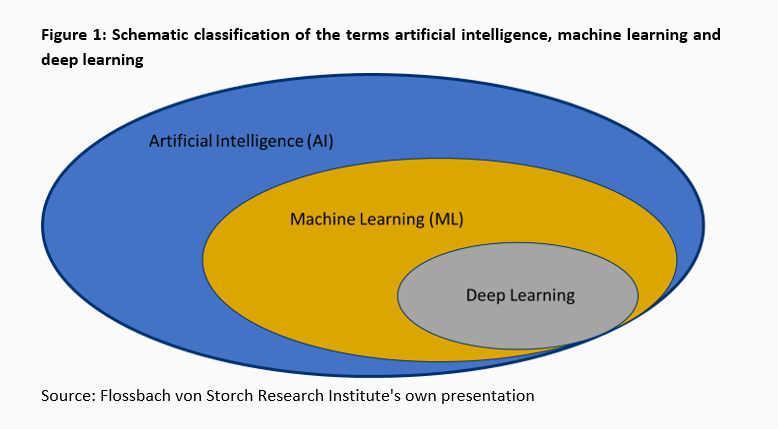
In 1989, machine learning made the next leap. Yann LeCun programmed an algorithm that could distinguish the digits on handwritten cheques with the help of a so-called neural network. The system looked at already classified digits, analysed the pixel structure and then independently developed a structure to later classify unknown digits. The only input and output were specified, as well as the "neural network" method. This subfield of ML, which is very popular today, is therefore called deep learning.
In more advanced forms of deep learning, the models are given additional freedom over the output. In 2012, in the so-called "Cat Experiment", Google fed a neural network with ten million randomly selected images under the general guideline of recognising recurring patterns. The result was a system that recognised cats and human faces, among other things.1
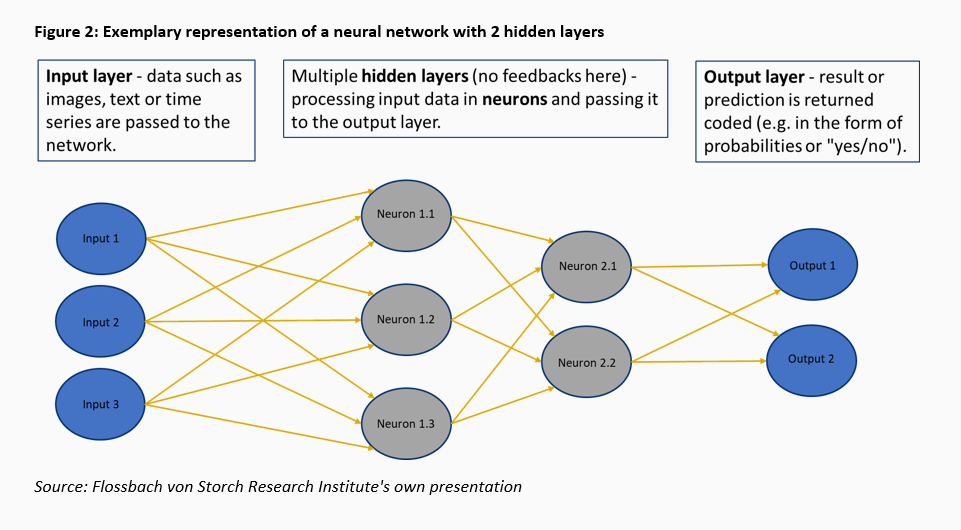
Instead of estimating the future price of a share on the basis of a given model using regression, for example, as in classical statistics, machine learning searches through large amounts of data for patterns. As a rule, no economic assumptions are made in advance. You can think of this as a dance floor with thousands of dancing couples, where you want to predict the trajectory of a single couple while all the couples influence each other. It is difficult to imagine being able to represent this by a mathematical model defined in advance. Ideally, the machine encounters correlations that remain hidden to the human eye. Computers benefit from being able to process a disproportionately larger amount of data in the same amount of time as humans and not suffer from psychological effects such as cognitive distortions.
We have summarised a tabular comparison of the most important conceptual differences of the classical statistical approach against that of machine learning in Table 1. Further details can be found in the literature.2

A guide to what a value chain for creating and applying machine learning to financial markets might look like is described by former hedge fund manager Marcos López de Prado.3
At the beginning of the value chain is the collection, cleansing, indexing, adaptation and storage of information. The information can come from a wide variety of sources and is not limited to financial market data and company information. It can be structured or unstructured, available as text, in figures or even videos. The quality of the information collected is crucial for the success of the processes based on it, because the result cannot be better than the information content of the data.
The second step is to use ML to identify patterns in the raw data that are related to financial ratios. Third, strategists are given the task of formulating actions based on the identified patterns. The strategists are faced with the task of formulating theses on the patterns that can explain the economic processes. This is to ensure that it is not a random finding that cannot be explained causally. In retrospect, the recognised pattern should be seen as a test for the theses. The "black box" of the pattern found is to become an understood "white box". In the fourth step, the actions are put to the test by means of backtesting. Just because a pattern was successfully exploited in the past does not necessarily mean that this will be the case in the future. For this purpose, different time periods can be used or data itself can be simulated.
After a successful backtest, it is time for implementation. The action must be integrated into the existing systems and processes as the fifth step and it must be ensured that there is no time lag between the recognition of patterns and the action that would make the action obsolete.
If the technical implementation is successful, the action can be included in the operational process. The success, the risk and the costs of the ML-based action must be constantly monitored. Sooner or later, the patterns in the data may have changed and can no longer be exploited because, for example, others have become aware of the pattern and are also trying to exploit it. The development and implementation of pattern recognition and subsequent actions must take place permanently so that discarded actions can be replaced and one can always adapt to changing framework conditions.
Functioning approaches to pattern recognition represent the "heart" of the value chain and must be protected accordingly in order to preserve the competitive advantage. In contrast, the basic methods are not a trade secret and can be found as freely available versions on the internet. For example, a search on the online portal for open source programmes github.com for the term "stock price prediction" produces 854 results.4 This is not to say how good these publicly available approaches are.
After this theoretical introduction, we will look at practical implementations in the following.
The best-known pioneers in the practical use of algorithms in finance are the mathematician Jim Simons and his company Renaissance Technologies and Ray Dalio, the founder of Bridgewater Associates. Both attempted to formalise securities trading and automate decisions with the help of computers as early as the 1980s. They are convinced that financial markets follow certain patterns. Simons began with "mean-reverting" and trend-following algorithms.5 Today, however, according to him, more refined methods are necessary. The investment horizon is always "short-term". He holds his positions for a maximum of two weeks.6
Ray Dalio also started early with the mathematical formalisation of economic relationships. He often describes the economy as an "economic machine". In his view, it is a huge web of interrelationships of cause and effect, and resembles a machine of interlocking gears. The firm he founded, Bridgewater, strives to replicate and refine these interrelationships as accurately as possible. His first model of the bond market fit on an A5 page.7
But where do these and other companies stand today? According to Greg Jensen, Co-CIO of Bridgewater, Bridgewater's goal is still to map all decisions into algorithms and automate them.8 The employees focus on the further development of the models. By adding new data and input parameters, the forecasting methods are refined, plausibilised and tested before they expand the corpus of existing algorithms in "real" operation. Machine learning also plays a role in the methods used. Jenson describes the results as follows:
Jensen vehemently disagrees with the argument that machine learning is a "black box" for humans. In the development process of new models, which as described above is always supervised by humans, Bridgewater would ask the software various questions in order to understand its behaviour. Translated, this probably means experimenting with different input parameters and interpreting the results. The analogy to human interaction that Jensen draws is interesting: Why a person gives a certain answer to a certain question often cannot be explained. In the course of a conversation, however, one gets an idea of the individual's motives through several answers to different questions. You understand their logic of action.
For Jensen, machine learning is an evolution of algorithms. It gives the user advantages in concrete trading decisions. Obviously, there is still a lack of trust in ML to recognise long-term developments. We will now give concrete examples from the financial sector, following the hierarchy reported by Jensen. We start with trading and transaction costs, move on to risk management tools and conclude with (long-term) predictions and their challenges.
Greg Jensen's statement that ML is already proven in trading seems plausible to us. According to a recent survey, 57 percent of participants trade more than 50 percent of their volume via algorithms.10 Estimates from 2018 suggest that 60 to 75 percent of volume in the US equity market is traded algorithmically.11 There are a number of companies offering services in this area. There is therefore much to suggest that this area is the most advanced in terms of ML. One of the reasons is probably a common interest of all market participants: the reduction of transaction costs through a sufficiently liquid market. Since every market participant acts as a buyer and a seller, everyone benefits from reliable prices or calculable spreads.
In a publication on the state of ML research, JP Morgan mentions the company Deltix as a specialist provider of trading software.12 Deltix itself is reticent about using the term ML, but in an article from 2017, top manager Stuart Farr speaks of adaptive algorithms that use real-time data as the holy grail of order execution algorithms.
Jeff Bacidore, former Head of Algorithmic Trading at Goldman Sachs, provides more detailed insights into reasons and methods on the website of his own company Bacidore LLC: In contrast to the actual price movements, the daily patterns of traded volumes as well as volatility and spreads are more consistent. The patterns change only slowly over time. For example, the traded volumes within a trading day in the US have the shape of a "J". Spreads follow a distorted "S" laid on its side.13 Trading, Bacidore continues, was traditionally driven by statistical methods. Now, the vast amounts of data generated daily and the increasing power of computers are opening up opportunities for machine learning.14
As an example, Bacidore mentions the further development of the volume-weighted-average-price strategy. Here, large orders are divided into partial packages in order not to negatively influence the price through one's own actions. Stocks are grouped into different "buckets" based on their characteristics, such as membership in an index or daily trading volume. A trading scheme is then created for each bucket, i.e. the size of the sub-packages and the times at which they are placed on the market are determined. This requires a lot of manual work. With the help of "k-means" algorithms, this process can be automated. Based on given input variables, the algorithm groups the different stocks into trading strategies based on their similarity, which it determines itself. Only the number of clusters is still chosen by the human, although quantitative aids are already given for this as well.
The algorithm can also be used to classify the trading strategies used in a company. This creates an overview of the trading behaviour of a financial actor. We would assign this to risk management, which we will illuminate later with further examples.
Another indication of the advanced use of ML in trading is the acquisition of Liquidnet, a provider specialising in ML trading, by Tullet Prebon, one of the largest inter-bank brokers in the world.15 Liquidnet's products are used in 46 markets worldwide, including the US and China. Liquidnet had itself expanded its AI operations in 2019 through the acquisition of Prattle.16 Prattle was a specialist in the field of Natural Language Processing, i.e. the reading of texts by machines and sentiment analysis.
For Liquidnet, the acquisition of Prattle was the last in a series of several acquisitions. The end product was a software module called Investment Analytics, which uses AI methods and bundles other functions in addition to classic trading support.17 The purchase by Tullet Prebon is a clear indication that trading support has outgrown its infancy and the market is consolidating, with established houses buying technology.
In addition, we see other established financial service providers offering software solutions in the area of trading. Examples are Citigroup18 and the Royal Bank of Canada (RBC).19 RBC uses so-called "reinforced learning" for this purpose. The algorithms used adapt independently based on feedback from transactions and thus react dynamically to new situations.
Since 2017, Japan's Government Investment Fund (GPIF), the world's largest pension fund, under its CIO Hiromichi Mizuno, has been tackling the topic of ML in risk management in a partnership with Sony Computer Science Laboratories. Mizuno is convinced of the possibilities of AI. In his words, it sounds like this:
"We're just trying to prove, even the boring organisations like the GPIF can benefit from AI to send a message (that) the industry should be able to benefit much more from AI adaptation."20
GPIF does not invest parts of its client money itself, but in actively managed funds.21 ‑ However, the results of the (equity‑) funds were considered disappointing. Therefore, GPIF and Sony are trying to improve the selection and monitoring process with the help of ML. In the first step, eight investment styles were defined. The "High Dividend" style, for example, stands for a strategy that favours stocks with high historical dividends. Other strategies were "Minimum Volatility", "Momentum", "Value", "Growth", "Quality", "Fixed Weight" and "Technical".22 Virtual funds were then created that aligned with these strategies in order to be able to train a neural network.
For the actual training, 19 factors, such as the price of a share and dividends, but also market data and fund-specific data, were considered over a rolling time horizon of 40 days for 100 shares. From these 76,000 inputs, eight neural networks were created, which indicate as output the percentage of a fund that follows one of the eight styles. The result was a machine that correctly assigned the virtual funds to the investment styles.23 The algorithm then analysed the styles of actively managed funds in which GPIF is invested. In addition to funds that remained "true to their line", the model also mapped the change from "momentum" to "growth" style in one case. This coincided with personnel changes in fund management.
In the course of further research, the factors influencing the differences between various funds were analysed. Comparing a fund held in the portfolio and a "candidate" fund, the software confirmed the preference for an industry sector and a specific individual stock as the main difference between the two funds, which was also found through classical analysis. In addition to this confirmation, the algorithm provided visualisations of the risk positions of all funds held, which increases the clarity over the portfolio.24
Further research is concerned with forecasting the risk structure of funds when economic conditions change. In particular, it explores whether shifts in individual fund portfolios can be predicted and what this means for the fund's risk position. This goes beyond a static stress test, as it not only changes the economic parameters, but also tries to predict the reactions to them. The results have not yet been published.
Another application for risk management is shown by the American hedge fund house TwoSigma Investments under the term regime modelling.25 The aim was to classify the past since 1970 into different macroeconomic states. Based on 17 factors, the algorithm was free to determine the number of different regimes independently. A so-called Gaussian mixture model was used, which learns without human input and can also map tail risks by combining several normal distributions.
The model divided the past into four states - each state has a 17-dimensional normal distribution including the mean values, variances and covariances between the influencing factors. It did not use any theories and did not give the scenarios names. The TwoSigma researchers subsequently named the scenarios based on their own associations. They decided on the eloquent names "Crisis", "Steady State", "Inflation" and "Walking on Ice", whereby walking on ice does not necessarily have to be followed by a crisis-like collapse, but only refers to a phase characterised by uncertainty. Sometimes one reaches the other shore dry-footed and continues on stable ground.
No prediction is possible in this model either. But the result is still suitable for risk management: if you believe that the algorithm has found the "essential" four macroeconomic states, you cannot predict which scenario will occur next, but you can position yourself in such a way that your portfolio shows a robust performance under each of the four scenarios. In any case, it stimulates reflection on macroeconomic issues, thus acting as the "hint machine" mentioned by Greg Jensen.
Renaissance Technologies has been using machine learning to predict prices in the short term for some time, as Simons explains in an interview.26 According to his own information, Renaissance's flagship, the Medaillon Fund, achieved an average return of 44 percent per year.27 The methods used are advanced trading algorithms that can identify anomalies with a certain probability on the basis of data collected over many years. Individual positions are held for a maximum of one to two weeks.28 The amount of the bets is probably determined according to the Kelly criterion, a mathematical formula which determines how much capital an investor should invest depending on the estimated chances of winning and the expected profit.29 In any case, the decisions are all made entirely by the machine. According to Simons, no human intervenes in the process on the basis of his gut feeling, even if the human could sometimes be in the right, as Simons admits. But he is concerned with the casino effect: the algorithm, weighted according to the capital invested, only has to be right more often than wrong - then the fund gains in value.
The success of the Medaillon Fund is confirmed by Warren Buffet and Charlie Munger.30 However, they also point out that the methods only work as long as the volume is kept within a certain range, as otherwise the anomalies are "eaten up" by one's own trading activities - an argument that Simons also mentions. In addition, Buffet and Munger point out that the algorithms are not equally convincing for long-term investing, which is confirmed by the performance of Renaissance's long-term oriented mutual fund.31 Buffet's answer to the question whether he and Munger would hire a data scientist for "short term" trading shows their appreciation for Simon's work, but also their own attitude:
"We do not know how to do it and we do not really trust anybody else to trade for us."32
The examples described above show that short-term prediction by ML can be very successful. It also cannot be ruled out that other companies below the radar, which are not mentioned here, use similar strategies with success. Due to the influence of their own actions on the market, it can be assumed that they proceed discreetly and trade with comparatively small volumes.
This in turn shows the current limitations of algorithms. Costs incurred cannot be offset by higher capital investment. The Medallion Fund is worth ten billion dollars, generating an average annual profit of 4.4 billion dollars. By comparison, Berkshire Hathaway had a market capitalisation of around 350 billion dollars in 2017, which has almost doubled since then. So if you had enough faith in Buffet and Munger, leveraged investing in Berkshire could have generated higher returns depending on your risk appetite.
In order to be able to trade larger volumes with AI in the future, one possible strategy is therefore to find algorithms that allow long-term predictions. The next section looks at some existing products of this kind.
Attempts to identify shares and create a profitable portfolio using machine learning have also reached the mutual fund sector. Products for this purpose can be found, for example, at AIEQ, ACATIS, DWS or Ampega.33 ML is used here to support fund managers in evaluating data or to make active decisions. The AIEQ Funds, which was launched in 2017 and uses IBM Watson to identify investment targets and allocate its portfolio, closed its fiscal year 2022 with a loss of almost 30 per cent, while the S&P 500 Index lost only 15 per cent in the same period.34 A study published in 2022 contests, based on a comparison of passive, active and AI-based investment funds, that AI-based investment funds in principle do not have higher price predictive power and that their risk-adjusted generated returns cannot distinguish themselves from the peer groups.35
There are even voices that consider long-term prediction to be fundamentally unpromising and advocate a focus on short-term forecasts under the term "More Nowcasting - Less Forecasting".36 In order to be able to trade high volumes, however, the algorithms would then have to be able to detect more significant anomalies. The former hedge fund manager Marcos López de Prado, mentioned above, cites the 30 percent price drop of the S&P 500 in the spring at the beginning of the Corona pandemic as an example that this is possible in principle. Very few "market makers" would have made losses at that time, as they had been warned early on of the coming price slide by imbalances of supply and demand in the order books. In addition, it is argued that the slide in stock market prices was preceded by an equally sharp and sudden drop in some commodity prices with a lead time of about four weeks due to the first lockdowns in China. It remains open whether this connection allows conclusions to be drawn about patterns of price shocks in general or whether it remains an individual phenomenon that is plausible in retrospect.
Even if one must always be aware that the machine learning methods of various hedge funds are not published and are kept secret especially when they are successful, it can nevertheless be assumed that sooner or later at least the information that a fund house is successful with long-term ML-based stock picking would become known. Whatever the outcome of this discussion, the bottom line is that as of today we are not aware of any algorithms that can profitably predict, for example, narrative changes or regime changes in the sense of Kleinheyer and Mayer's Discovering Market Hypothesis in the long term37 and thus offer real advantages in long-term prediction or the prediction of fundamental structural breaks.
The release of Chat-GPT has brought the latest artificial intelligence capabilities to the world's attention, even though approaches such as machine learning have been applied to the financial markets for some time.
In our view, there will be further efficiency gains in the future beyond reducing transaction costs and efficient risk warning systems. Although some ML approaches are already able to anticipate short-term price movements, it remains questionable whether algorithms will ever be able to anticipate long-term price movements on capital markets. Whether machines will outperform savvy investors like Warren Buffet and Charlie Munger remains to be seen. However, they already serve as extremely helpful technical support. If you don't want to be left behind by developments, you should stay tuned to this topic and follow the next steps closely, or even better, design them yourself.
1 A Brief History of Deep Learning - DATAVERSITY
2 Mueller & Massaron: "Machine Learning for dummies", 2nd ed., Tab. 1-1
3 Marcos Lopez de Prado: "Advances in Financial Machine Learning", John Wiley & Sons, New Jersey, 2018.
4 See github.com, retrieved 24.02.2023.
5 The mathematician who cracked Wall Street | Jim Simons - YouTube
6 Renaissance Technologies - Trading Strategies Revealed | A Documentary - YouTube and Renaissance Technologies - Wikipedia
7 Greg Jensen on Algorithmic Decision Making and Artificial Intelligence (bridgewater.com), screenshot of the original running time 4:30.
8 Greg Jensen on Algorithmic Decision Making and Artificial Intelligence (bridgewater.com)
9 Greg Jensen on Algorithmic Decision Making and Artificial Intelligence (bridgewater.com), running time 14:50.
10 Algorithmic-Trading-Survey-Long-Only-2022.pdf (thetradenews.com)
12 JPM-2017-MachineLearningInvestments.pdf (cpb-us-e2.wpmucdn.com)
13 Investing in Trader Alpha: A reliable, cost-effective way to boost performance (bacidore.com)
14 Applications of Machine Learning in Trading: Part 1 (bacidore.com)
17 Liquidnet Investment Analytics
19 From Artificial Intelligence to Trading Intelligence (rbccm.com)
20 CIO of Japan's GPIF praises AI technology | Pensions & Investments (pionline.com)
21 GPIF Annual Report 2021, p. 89.
23 GPIF / Sony CSL (2018), Fig. 2.3.
24 GPIF / Sony CSL (2020), Fig. 1.
25 Machine-Learning-Approach-to-Regime-Modeling_.pdf (twosigma.com)
26 James Simons (full length interview) - Numberphile - YouTube
27 The mathematician who cracked Wall Street | Jim Simons - YouTube
28 Medallion Fund Literally Printed Money in the Last 30 Years | Wealth of Geeks
29 Renaissance Technologies - Trading Strategies Revealed | A Documentary - YouTube and Kelly formula - Wikipedia
30 Warren Buffett & Charlie Munger On Jim Simons & Quant Investing - YouTube
31 Renaissance U.S. Equity Income Fund | Renaissance Investments
32 Warren Buffett & Charlie Munger On Jim Simons & Quant Investing - YouTube
33 E.g. AIEQ AI Powered Equity ETF, Acatis AI Global Equities , LI Data Intelligence Germany, DWS Concept ESG Arabesque AI Global Equity.
34 AIEQ: Shareholder Letter 2022
36 Lopez de Prado, Lipton (2020): "Three Quant Lessons from COVID-19), SSRN.





Legal notice
The information contained and opinions expressed in this document reflect the views of the author at the time of publication and are subject to change without prior notice. Forward-looking statements reflect the judgement and future expectations of the author. The opinions and expectations found in this document may differ from estimations found in other documents of Flossbach von Storch AG. The above information is provided for informational purposes only and without any obligation, whether contractual or otherwise. This document does not constitute an offer to sell, purchase or subscribe to securities or other assets. The information and estimates contained herein do not constitute investment advice or any other form of recommendation. All information has been compiled with care. However, no guarantee is given as to the accuracy and completeness of information and no liability is accepted. Past performance is not a reliable indicator of future performance. All authorial rights and other rights, titles and claims (including copyrights, brands, patents, intellectual property rights and other rights) to, for and from all the information in this publication are subject, without restriction, to the applicable provisions and property rights of the registered owners. You do not acquire any rights to the contents. Copyright for contents created and published by Flossbach von Storch AG remains solely with Flossbach von Storch AG. Such content may not be reproduced or used in full or in part without the written approval of Flossbach von Storch AG.
Reprinting or making the content publicly available – in particular by including it in third-party websites – together with reproduction on data storage devices of any kind requires the prior written consent of Flossbach von Storch AG.
© 2024 Flossbach von Storch. All rights reserved.